Understanding the Role of the [class] Token in Vision Transformers (ViT)
Discover how the “[class]” token in Vision Transformers consolidates image patch data, playing a crucial role in accurate image classification.

Introduction: The Power of Vision Transformers in Computer Vision
Problem: In traditional CNNs, image classification tasks rely on convolution layers that learn patterns from pixels. However, as we scale images and problems get more complex, the CNN approach struggles with long-range dependencies across pixels. This is where the Vision Transformer (ViT) shines — by splitting images into patches and processing them as sequences, just like text in NLP models. But there’s one part of this architecture that plays a crucial role in making this approach work: the “[class]” token.
What is the “[class]” Token?
Starting Simple — What Does “[class]” Mean?
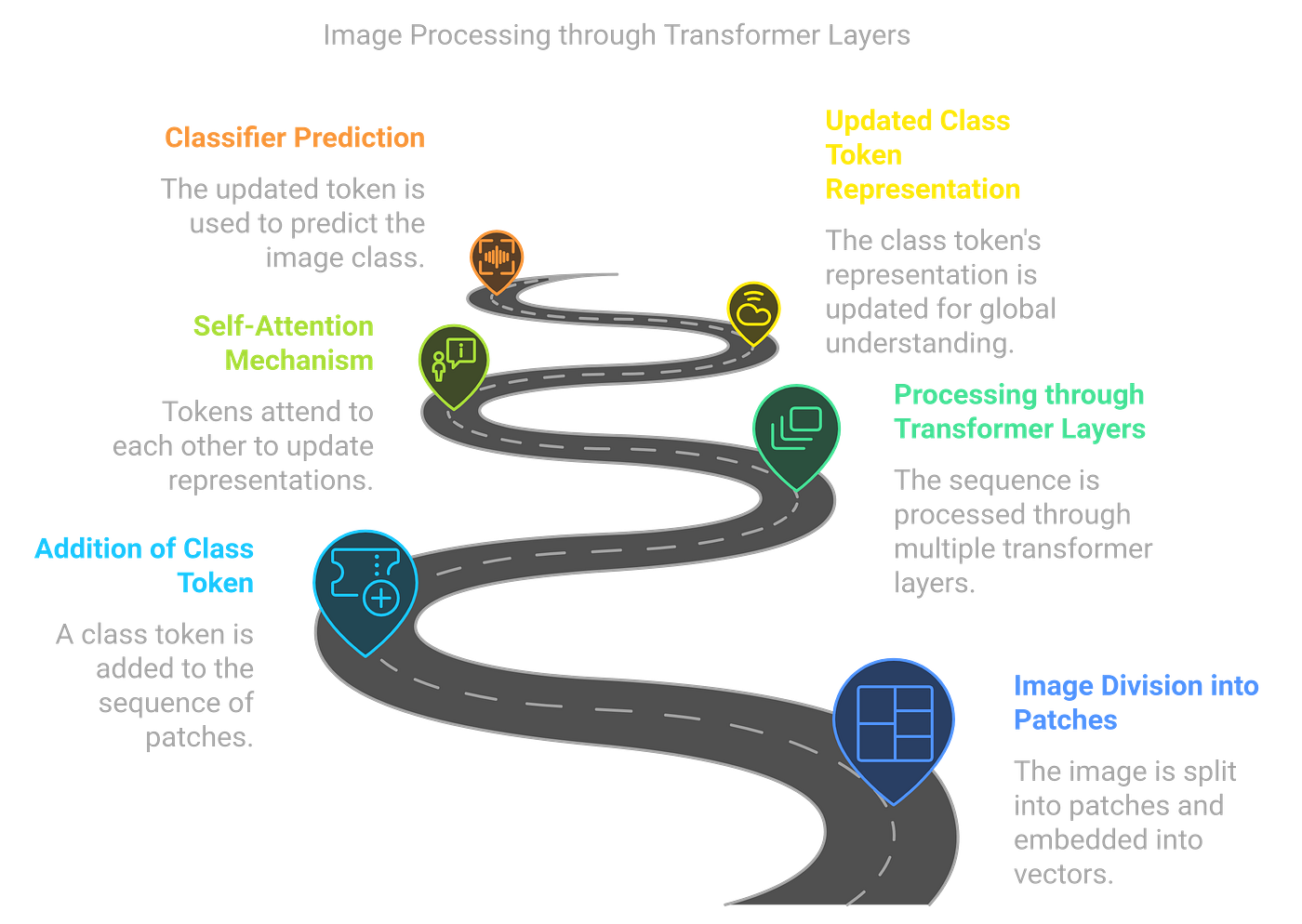
The “[class]” token is a special token used in Vision Transformers (ViTs) for classification tasks. Think of it as the “summary” or “digest” of the entire image. When you feed an image into a ViT, it’s divided into patches, and each of these patches is processed in parallel. The “[class]” token is introduced at the beginning of the sequence of image patches and holds the encoded features of the entire image.
- Simple Analogy: Imagine you’re reading a book, but instead of reading the entire book, you summarize it with a single sentence that captures the main theme. The “[class]” token is that sentence.
- Why it Matters: This token’s representation at the output layer helps the model decide what class the image belongs to. Without it, the model would only understand individual patches, without an overall understanding of the image.
How Does the “[class]” Token Work in the Vision Transformer?
The Token’s Journey Through the Transformer Layers
Once the image is split into patches and the “[class]” token is added, these patches (and the “[class]” token) pass through the Transformer’s layers. The key part of this process is self-attention: each token (including the “[class]” token) attends to every other token, allowing the model to learn the relationships between patches. This attention mechanism lets the model focus on the most relevant parts of the image to create a unified understanding.
- What Happens in the Layers?
In the Transformer layers, the self-attention mechanism updates the representation of the “[class]” token by incorporating information from all the patches. After multiple layers of attention, this token represents the collective understanding of the image.
The Key Role of the “[class]” Token in Image Classification
Connecting the Dots — From Image Patches to Class Predictions
At the end of the Transformer layers, the “[class]” token is used to make the final classification prediction. Essentially, the token now holds the aggregated, high-level features of the image, enabling the model to determine what the image represents. This process is similar to how BERT or GPT use a special token to predict outputs in NLP tasks.
- Before/After Code Example:
Here’s a basic example of how the “[class]” token works in code:
# Before self-attention layers
patches = extract_patches(image) # Split image into patches
tokens = [class_token] + patches # Add class token at the beginning
# After self-attention layers
output = transformer(tokens) # Pass through transformer layers
class_representation = output[0] # Class token at the output
prediction = classifier(class_representation) # Final predictionPro Tip: Ensure that your “[class]” token is trained to capture the right features by adjusting the size of your image patches. Too large, and the model might miss important details; too small, and it could become noisy.
Common Pitfalls and Troubleshooting
Gotcha! Don’t Make These Mistakes with the “[class]” Token
- Misunderstanding the Token’s Purpose: The “[class]” token isn’t just any token — it’s crucial for classification tasks. If it’s not included or improperly handled, the model won’t learn to represent the entire image.
- Gotcha! Token Initialization: Sometimes, the “[class]” token might not be initialized properly or might not learn effectively during training. Make sure it’s treated like any other token in the Transformer, with attention mechanisms allowing it to update.
- Pitfall: Too Small Patch Size
If your patches are too small, the “[class]” token might not get enough information about the image. On the other hand, if the patches are too large, you could lose fine-grained details.
Conclusion: Why the “[class]” Token is Crucial for Vision Transformers
In this article, we’ve explored how the “[class]” token in Vision Transformers serves as the essential component that consolidates all the image patches’ information and enables classification. It may seem like a small part of the architecture, but its impact is enormous. By attending to the global context of the image, it empowers ViTs to perform well on complex image classification tasks.